Loading Wikipedia articles (EN) with Python
Wikipedia is the largest and most popular general reference work on the World Wide Web, and is one of the most popular websites ranked by Alexa as of January 2020.
As of February 2020, there are 6,016,720 articles in the English Wikipedia containing over 3.5 billion words. There are a lot of information about the amount of data in Wikipedia that can be found in this article.
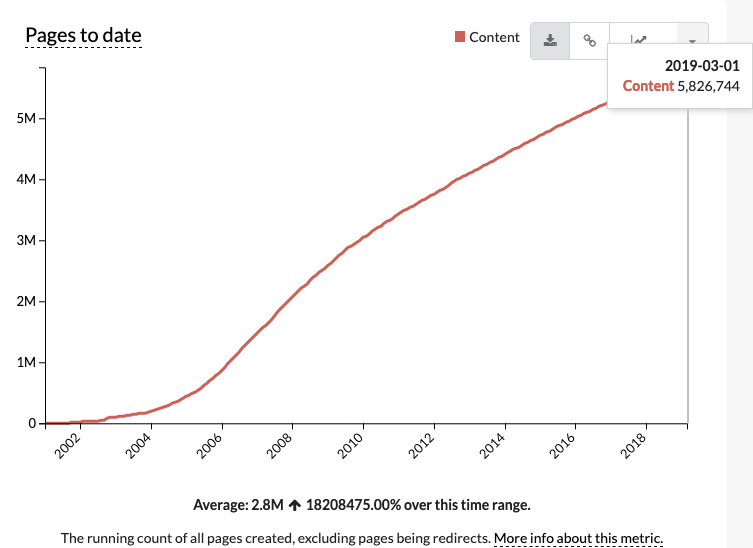
Content page count of the English-language Wikipedia from the beginning to 2019-03-21
This article is going to show you how to download the whole Wikipedia (in English) and load the data in Python.
You can dowload the original Notebook from my GitHub repository.
Downloading the Data
The fastest way of getting Wikipedia is though torrent. Download the last version of the data dump from this page. You should download the newest version of the file enwiki-YYYYMMDD-pages-articles-multistream.xml.bz2, where YYYYMMDD is the date of the dump.
The MD5 for the file can be found in the link http://ftp.acc.umu.se/mirror/wikimedia.org/dumps/enwiki/YYYYMMDD/md5sums-enwiki-YYYYMMDD-pages-articles-multistream.xml.bz2.txt where YYYYMMDD should be replace by the date of the dump.
After downloading the articles bz2 file, we need to download the list on indices for the articles from http://ftp.acc.umu.se/mirror/wikimedia.org/dumps/enwiki/YYYYMMDD/enwiki-YYYYMMDD-pages-articles-multistream-index.txt.bz2. Again, replace YYYYMMDD by the date of the dump.
After downloading the files you should extract only the index file. On Linux, we can use lbzip2 to uncompress the file using multiple CPUs, speeding up the process. In the terminal, in the file folder type:
$ lbzip2 -d enwiki-YYYYMMDD-pages-articles-multistream-index.txt.bz2
Loading the Data
Now is where the things start to become interesting. Since the file is too large to fit in memory, we are going to load it iteratively.
import pyarrow.parquet as pq
import pyarrow as pa
import pandas as pd
import numpy as np
import itertools
import os
import io
from multiprocessing import Pool
from tqdm import tqdm
from lxml import etree
import bz2
from bz2 import BZ2Decompressor
from typing import (
List, Generator
)
VERSION = '20200420'
# Path to the bz2 files with Wikipedia data
path_articles = f'enwiki-{VERSION}-pages-articles-multistream.xml.bz2'
# Path to the index list from Wikipedia
path_index = f'enwiki-{VERSION}-pages-articles-multistream-index.txt.bz2'
# Path to our cached version (for offsets)
path_index_clean = f'enwiki-{VERSION}-pages-articles-multistream-index_clean.txt'
# Path to the output parquet file
path_wiki_parquet = 'wiki_parquet/'
# Number of processors to be used during processing
n_processors = 16
# Number of blocks of pages to be processed per iteration per processor
n_parallel_blocks = 20
The multistream dump file contains multiple bz2 ‘streams’ (bz2 header, body, footer) concatenated together into one file, in contrast to the vanilla file which contains one stream. Each separate ‘stream’ (or really, file) in the multistream dump contains 100 pages, except possibly the last one. The multistream file allows you to get an article from the archive without unpacking the whole thing.
The index file contains the full list of articles. The first field of this index is the number of bytes to seek into the compressed archive pages-articles-multistream.xml.bz2, the second is the article ID, the third the article title. A colon (:) is used to separate fields.
Since we would like to extract all the articles from wikipedia, we don’t have to keep track of titles and IDs, only the offsets. Thus, we read the offsets and store them into a new file.
def get_page_offsets(path_index: str, path_index_clean: str) -> List[int]:
"""Get page offsets from wikipedia file or cached version
Wikipedia provide an index file containing the list of articles with their
respective id and offset from the start of the file. Since we are
interested only on the offsets, we read the original file, provided by
`path_index`, extract the offsets and store in another file (defined by
`path_index_clean`) to speed up the process
Args:
path_index (str): Path to the original index file provided by Wikipedia
(bz2 compressed version)
path_index_clean (str): Path to our version, containing only offsets
Returns:
List[int]: List of offsets
"""
# Get the list of offsets
# If our new offset file was not created, it gets the information
# from the index file
if not os.path.isfile(path_index_clean):
# Read the byte offsets from the index file
page_offset = []
last_offset = None
with open(path_index, 'rb') as f:
b_data = bz2.decompress(f.read()).split(b'\n')
# Drop the last line (empty)
if b_data[-1] == b'':
b_data = b_data[:-1]
for line in tqdm(b_data):
offset = line.decode().split(':', 1)[0]
if last_offset != offset:
last_offset = offset
page_offset.append(int(offset))
with open(path_index_clean, 'w') as f:
f.write(','.join([str(i) for i in page_offset]))
else:
with open(path_index_clean, 'r') as f:
page_offset = [int(idx) for idx in f.read().split(',')]
return page_offset
Parsing the data
In order to parse the files, we need to open the bz2 file containing the articles, read blocks of bytes, according to the offsets defined above, and then uncompress these blocks.
The generator get_bz2_byte_str reads the blocks sequentially, following the list of offsets. And the function get_articles is used to convert each byte string into a pandas data frame containing the index, title and content of the article.
Note: The XML structure can be found on this page.
def get_bz2_byte_str(path_articles: str,
offset_list: List[int]) -> Generator[bytes, None, None]:
"""Read the multistream bz2 file using the offset list
The offset list defines where the bz2 (sub)file starts and ends
Args:
path_articles (str): Path to the bz2 file containing the Wikipedia
articles.
offset_list (List[int]): List of byte offsets
Yields:
bytes: String of bytes corresponding to a set of articles compressed
"""
with open(path_articles, "rb") as f:
last_offset = offset_list[0]
# Drop the data before the offset
f.read(last_offset)
for next_offset in offset_list[1:]:
offset = next_offset - last_offset
last_offset = next_offset
yield f.read(offset)
def get_articles(byte_string_compressed: bytes) -> pd.DataFrame:
"""Get a dataframe containing the set of articles from a bz2
Args:
byte_string_compressed (bytes): Byte string corresponding to the bz2
stream
Returns:
pd.DataFrame: Dataframe with columns title and article
"""
def _get_text(list_xml_el):
"""Return the list of content for a list of xml_elements"""
return [el.text for el in list_xml_el]
def _get_id(list_xml_el):
"""Return the list of id's for a list of xml_elements"""
return [int(el.text) for el in list_xml_el]
bz2d = BZ2Decompressor()
byte_string = bz2d.decompress(byte_string_compressed)
doc = etree.parse(io.BytesIO(b'<root> ' + byte_string + b' </root>'))
col_id = _get_id(doc.xpath('*/id'))
col_title = _get_text(doc.xpath('*/title'))
col_article = _get_text(doc.xpath('*/revision/text'))
df = pd.DataFrame([col_id, col_title, col_article],
index=['index', 'title', 'article']).T
df['index'] = df['index'].astype(np.int32)
return df
Reading and storing in parquet files
We read the blocks of the bz2 file, extract the data and write to parquet files. In order to speed up the process we use a queue to store the blocks of bytes that are processed in parallel.
I was having problems to load the index using dask, so I decided to store it as a column and drop the pd.DataFrame index.
def chunks(input_list: List, chunk_size: int) -> Generator[List, None, None]:
"""Split a list into chunks of size `chunk_size`
Args:
input_list (List): Input list
chunk_size (int): Size of the chunks. Note that the last chunk may have
less than `chunk_size` elements
Yields:
Generator[List, None, None]: Sublist of size `chunk_size`
"""
# For item i in a range that is a length of l,
for i in range(0, len(input_list), chunk_size):
# Create an index range for l of n items:
yield input_list[i:i+chunk_size]
def _process_parallel(list_bytes: List[bytes]) -> None:
"""Process a subset of the byte chunks from the original dump file
Args:
list_bytes (List[bytes]): List of byte strings (chunks from the
original file)
"""
df = pd.concat([get_articles(article) for article in list_bytes])
output_path = (
os.path
.join(path_wiki_parquet,
'{:08d}.parquet'.format(df['index'].values[0]))
)
# Save the index as a column and ignore the df index
df.to_parquet(output_path, compression='snappy', index=False)
# Clear the data tables
del df
The code bellow stores each block of 100 articles in a new parquet file. It allows you to load a subset of the full dump or work using Dask, Modin or pySpark.
I am using Snappy to reduce the amount of space used by the extracted data.
Snappy (previously known as Zippy) is a fast data compression and decompression library written in C++ by Google based on ideas from LZ77 and open-sourced in 2011. It does not aim for maximum compression, or compatibility with any other compression library; instead, it aims for very high speeds and reasonable compression.
queue = []
page_offset = get_page_offsets(path_index, path_index_clean)
# Read the file sequentially
for bit_str in tqdm(get_bz2_byte_str(path_articles, page_offset), total=len(page_offset)):
# Feed the queue
if len(queue) < n_processors * n_parallel_blocks:
queue.append(bit_str)
# Decompress and extract the infomation in parallel
else:
with Pool(processes=n_processors) as pool:
tuple(pool.imap_unordered(_process_parallel, chunks(queue, n_parallel_blocks)))
# Clean the queue
for el in queue:
del el
queue.clear()
# Run one last time
with Pool(processes=n_processors) as pool:
tuple(pool.imap_unordered(_process_parallel, chunks(queue, n_parallel_blocks)))
# Clean the queue
for el in queue:
del el
queue.clear()
Next Steps
Done! Now, we can load the data from parquet.
However, we still have to parse the data from the articles, since there are some markups used to Wikipedia for citations, info boxes, categories and so on. We will deal with these in the next artile.